

NoSQL: Um comparativo de ferramentas para a administração do MongoDb
Por Rogério Marques
06 julho 2018 - 15:03 | Atualizado em 29 março 2023 - 17:32

Este artigo tem por objetivo apresentar os principais conceitos relacionados ao nosql em especial o mongodb, um sistema de gerenciamento de banco de dados de software livre (como a maioria dos sgbds nosql), sendo orientado a documentos e escrito em C++.
O artigo também tem por objetivo mostrar as principais ferramentas para gestão de dados no MongoDB, que facilitam em muito a criação dos principais objetos neste Banco de Dados.
Ferramentas como o nosql manager, shell mongodb, mongovue, linqpad, rest view, genghis, mongodbmonitoringservice (monitoramento de uma instancia mongodb), studio 3t e o robomongo.
Além disto, mostra um pequeno estudo comparativo destas ferramentas, suas principais vantagens, com destaque para o robomongo, que além de ser uma ferramenta gratuita, apresenta uma série de recursos que podem ser utilizados no gerenciamento e na criação de Bancos e objetos nosql no mongodb.
NoSql
O termo nosql aparece pela primeira vez como conceito e termo fundamentado em 1998, nomeado inicialmente como banco de dados relacional de código aberto, que tinha como característica principal não possuir uma interface SQL. Seu autor, Carlo Strozzi, alegava que o movimento nosql era completamente distinto do modelo relacional, nomeando este modelo de “norel”, ou mesmo outro termo que produzisse o mesmo efeito proporcionado por este.
Depois disto o termo passou por uma “repaginada” relacionada a conceitos e em meados de 2009 apareceu novamente. Desta vez foi Eric Evans, um funcionário da rackspace, que através de um evento que tinha como objetivo principal a discussão de bancos de dados ‘open source’ distribuídos. Nisto o nosql, ganha novos contornos e definições, onde em sua primeira aparição as suas definições queriam apenas uma distinção do modelo relacional e aqui ele (o termo) pretende descrever o surgimento cada vez mais frequente e constante de bancos de dados não relacionais, que em sua característica principal não tem mais a preocupação central de fornecer garantias ‘acid’.
A questão não relacional vai envolver o não uso de transações ‘acid’, lembrando que alguns nosql, suportam transações multi-registros, mas não algo ‘’full acid’. Estes bancos não possuem sql, mesmo que alguns nosql possuam linguagens de consulta inspiradas em sql e por último a não existência de tabelas em alguns modelos, não podendo ser esquecido que alguns nosql possuem tabelas em sua composição.
ACID (atomicity, consistency, isolation, durability):
Acrônimo de atomicidade, consistência, isolamento e durabilidade, onde atomicidade ocorre quando todas as transações em uma operação são executadas em caso de sucesso ou nenhum resultado é refletido sobre a base de dados em caso de falha. Consistência ocorre sempre que na execução de uma transação um banco de dados passa de um estado consistente a outro estado consistente, deixando e respeitando a integridade da base de dados. O isolamento garante que uma transação paralela não vai interferir nas outras transações. A durabilidade garante que uma transação em caso de sucesso (commit), deva persistir no banco de dados mesmo em presença de falhas, garantindo que os dados estarão disponíveis em definitivo.
As origens nosql com sua primeiras e mais importantes implementações são provenientes de artigos publicados pelo Google (bigtable), com o surgimento de banco proprietário de alta performance, escalabilidade e disponibilidade e a amazon (dynamo), que é banco não-relacional com alta disponibilidade, sendo utilizado pelos ‘web services’ da amazon, surgidos em 2004 e 2007 respectivamente.
Em sua definição mais breve nosql, significa, ‘not only sql’, ou em sua tradução ‘não somente sql’, e de acordo com Sadalage J.Pramod e Fowler Martin estes bancos não possuem uma definição muito clara, geralmente sendo aplicado a alguns bancos de dados não relacionais recentes, que utilizam esquema e são executados em ‘clusters’ e trocam a consistência tradicional por outras propriedades úteis.
Considerando uma definição mais genérica, nosql, significa um banco de dados distribuído, não relacional, criado para trabalhar com grande quantidade de dados, utilizando servidores por vezes menores e com custo na maioria das vezes reduzido.
A questão de ser um banco de dados Distribuído pode ser entendida a partir de três conceitos básicos e que são compreendidos pelo particionamento dos dados (‘Sharding’ – Particionamento Horizontal), o balanceamento de carga e por último e não mesmo importante a tolerância a falhas.
Sharding:
É um conceito simples que usa divisão de dados entre várias máquinas quando o sistema de discos esta no limite ou mesmo falta espaço. O rendimento é maior e também a capacidade de armazenamento em disco com possibilidades de crescimento em termos de armazenamento apenas acrescentando mais Shards.
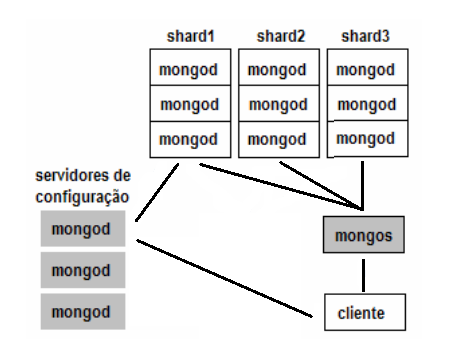
O particionamento dos Dados é uma funcionalidade que tem por objetivo facilitar a organização e o armazenamento de dados nos bancos nosql, e usa o recurso de dividir para alcançar performance e com isto apresenta alternativas que ajudam a melhorar a busca de dados nos bancos utilizados. O particionamento é passo necessário na implementação de soluções que possam prover alta disponibilidade e processamento paralelo distribuído.
O balanceamento de carga proporciona o uso de recursos compartilhados e que podem somar quando se precisa de performance nos recursos utilizados. Balancear carga significa, distribuir recursos e utilizá-los de forma distribuída, implementando-os de forma que possam resultar em processos balanceados a nível máximo, obtendo-se com isto valor agregado.
A tolerância a falhas entre bancos nosql leva em conta a replicação automática dos dados para vários nós (servidores na rede), onde a replicação para os vários centros de dados é suportada e nós que falham podem automaticamente serem substituídos sem que ocorra tempo alto de inatividade. Mesmo com falhas isto não vai afetar o ambiente em utilização. Esta tolerância a falhas leva em conta que mesmo que um dos nós de dados falhe o ambiente ainda ficará disponível, já que os outros nós ficarão disponíveis na rede facilitando todo o processo de replicação.
Em síntese o nosql possui alguns tipos e modelos principais em se tratando de suas arquiteturas:
– Chave-Valor: São os tipos nosql que apresentam a maior escalabilidade dos modelos existentes, sendo o mais simples e o que suporta mais carga de dados. Seu conceito é composto por uma chave e um valor para esta chave.
– Família de Colunas: Este tipo nosql, oferece suporte a várias linhas, colunas e subcolunas. Além disto, é fortemente inspirado no ‘bigtable’ da google.
– Documentos: O tipo documento tem por característica o uso de documentos que são baseados em ‘xml’ ou ‘json’, podendo ser localizados pelo seu ‘id único’ ou mesmo por qualquer registro que tenham no documento.
– Grafos: Os do tipo grafos guardam objetos e não registros e por isto apresentam uma complexidade maior.
– Orientados a Coluna: São bancos de dados relacionais que possuem características do nosql, sendo a sua principal diferença a forma de armazenamento que é feita em colunas, o que ajuda na sua escalabilidade.
MongoDb
Esta foi a primeira parte do artigo: NoSQL: Um comparativo de ferramentas para a administração do MongoDb
Na segunda parte, falaremos sobre o mongodb, um banco orientado a documentos, criado em 2009 pelos fundadores do ‘doubleclick’, que se basearam em suas experiências de construção em grande escala, alta disponibilidade e sistemas robustos para criar um novo tipo de banco de dados. Confira a Parte 2 aqui!



Deixe um comentário